





昨天在工作的时候,有一个最近上线的项目。
运维告诉我有一个sql查询居然长达14秒,那我肯定不能忍啊,决定要优化一下。
我是首先看了下代码,觉得和它没关系,然后拿到sql,再对比下生产上表的索引,竟然没有针对这sql的索引!
怎会如此粗心!心痛啊!
让运维帮忙拿到了生产上sql的执行计划explan,确定解决方案就是加个索引。
为了测试,我创建了一张表
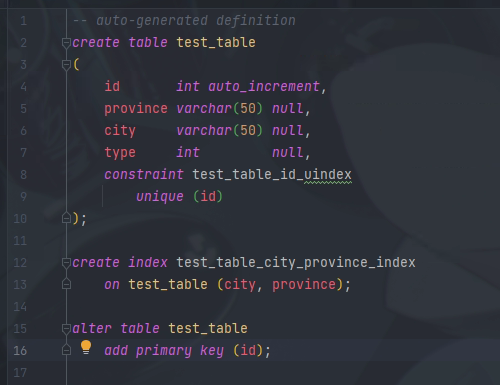
这张表针对city与province创建了一个复合索引
type是没有索引的
看懂执行计划
好久没用过mysql了,已经拉跨了。
首先执行计划只能应用于select,而且并不是很精准,得到的信息也很有限,不过用来排查问题优化sql还是很方便的。
EXPLAIN + SELECT 查询语句,就可以得到执行计划

执行计划这么些个列都是什么含义呢?
|
列名 |
含义 |
|---|---|
|
id |
id 列,表示查询中执行 select 子句或操作表的顺序。 |
|
select_type |
查询类型,主要是用于区分普通查询、联合查询、子查询等复杂的查询。 |
|
table |
表明对应行正在访问的是哪个表。如果是临时表 如dual就不会有表名,派生表derived |
|
partitions |
查询涉及到的分区。 |
|
type |
访问类型,决定如何查找表中的行。 |
|
possible_keys |
查询可以使用哪些索引。 |
|
key |
实际使用的索引,如果为 NULL,则没有使用索引。 |
|
key_len |
索引中使用的字节数,查询中使用的索引的长度(最大可能长度),并非实际使用长度,理论上长度越短越好。 |
|
ref |
显示索引的那一列被使用。 |
|
rows |
估算出找到所需行而要读取的行数。 |
|
filtered |
返回结果的行数占读取行数的百分比,值越大越好。 |
|
Extra |
额外信息,但又十分重要。 |
1.id
id 列是一个编号,用于标识查询的序列号,表示执行 SQL 查询过程中select子句或操作表的顺序。
如果在 SQL 中没有子查询或关联查询,那么 id 列都将显示一个 1。
否则,内层的 select语句一般会顺序编号。
id 列分为三种情况:
1.都相同,没有子查询
2.都不同 如果存在子查询,id 的序号会递增,id 值越大优先级越高,越先被执行。
3.以上都有 id相同的为同一组,同一组的从上向下
2.select_type
表示对应行的查询类型,是简单查询还是复杂查询
|
select_type 值 |
说明 |
|---|---|
|
SIMPLE |
表示最简单的 select 查询语句,也就是在查询中不包含子查询或者 |
|
PRIMARY |
当查询语句中包含任何复杂的子部分,最外层查询则被标记为 |
|
SUBQUERY |
当 |
|
DERIVED |
表示包含在 |
|
UNION |
如果 |
|
UNION RESULT |
代表从 |
3.table
表示对应行正在执行的哪张表,指代对应表名,或者该表的别名 (如果 SQL 中定义了别名)。
4.partitions
查询涉及到的分区
MySQL 数据库在 5.1 版本及以上时添加了对分区的支持,分区的过程是将一个表或索引分解为多个更小、更可管理的部分。
分区其实不太常用,在定义表的时候可以使用 PARTITION BY定义。
目前MySQL支持范围分区(RANGE),列表分区(LIST),哈希分区(HASH)以及KEY分区四种。
就访问数据库的应用而言,从逻辑上讲,只有一个表或一个索引,但是在物理上这个表或索引可能由数十个物理分区组成。每个分区都是独立的对象,可以独自处理,也可以作为一个更大对象的一部分进行处理。
5.type
指代访问类型,是 MySQL 决定如何查找表中的行
它 SQL 查询优化中一个很重要的指标,拥有很多值,依次从最差到最优:
ALL < index < range < index_subquery < unique_subquery < index_merge < ref_or_null < fulltext < ref < eq_ref < const < system
1.ALL
全表扫描,表示通过扫描整张表来找到匹配的行,很显然这样的方式查询速度很慢。
这种情况,性能最差,如果表数据很大的话,在写 SQL 时尽量避免此种情况的出现。
在平时写 SQL 时,避免使用 select * 为了避免全表扫描,因为全面扫描是性能最差的。

2.index
全索引扫描,和全表扫描 ALL 类似,扫描表时按索引次序进行,而不是按行扫描,即:只遍历索引树。
index 与 ALL 虽然都是读全表,但 index 是从索引中读取,而 ALL 是从硬盘读取。显然,index 性能上优于 ALL,合理的添加索引将有助于性能的提升。


index 与 ALL 虽然都是读全表,但 index 是从索引中读取,而 ALL 是从硬盘读取。显然,index 性能上优于 ALL,合理的添加索引将有助于性能的提升。
从执行计划看,type列没有添加索引,走了全表扫描。
3.range
只检索给定范围的行,使用一个索引来选择行。key 列显示使用了那个索引。一般就是在 where 语句中出现了 bettween、<、>、in 等的查询。这种索引列上的范围扫描比全索引扫描 index 要好。
4.index_merge
使用了索引合并优化方法,查询使用了两个以上的索引。
5.ref
非唯一性索引扫描,返回匹配某个单独值的所有行。本质是也是一种索引访问,它返回所有匹配某个单独值的行,然而它可能会找到多个符合条件的行,所以它属于查找和扫描的混合体。
此类型只有当使用非唯一索引或者唯一索引的非唯一性前缀时,才会发生。
6.eq_ref
唯一索引扫描。常见于主键或唯一索引扫描。
7.const
顾名思义 常数,通过索引一次就能找到,const 用于比较 primary key 或者 unique 索引。因为只需匹配一行数据,所有很快。如果将主键置于 where 列表中,mysql 就能将该查询转换为一个 const。
8.system
表只有一行记录,这是 const 类型的特例,比较少见,如:系统表。
6.possible_keys
显示在查询可以使用哪些索引,可以使用不代表执行时使用了这个索引。
7.key
实际使用的索引,如果为 NULL,则没有使用索引。查询中如果使用了覆盖索引,则该索引仅出现在 key 列中。
possible_keys 列表明哪一个索引有助于更高效的查询,而 key 列表明实际优化采用了哪一个索引可以更加高效。
单列索引,那么需要将整个索引长度算进去;
多列索引,不是所有列都能用到,需要计算查询中实际用到的列。
注意:key_len 只计算 where 条件中用到的索引长度,而排序和分组即便是用到了索引,也不会计算到 key_len 中。
8.key_len
表示索引中使用的字节数,查询中使用的索的长度(最大可能长度),并非实际使用长度,理论上长度越短越好。key_len 是根据表定义计算而得的,不是通过表内检索出的。
9.ref
表示在 key 列记录的索引中查找值,所用的列或常量 const。
10.rows
估算出找到所需行而要读取的行数。
这是评估 SQL 性能的一个比较重要的数据,mysql 需要扫描的行数,很直观的显示 SQL 性能的好坏,一般情况下 rows 值越小越好。
11.filtered
这个是一个百分比的值,表里符合条件的记录数的百分比。简单点说,这个字段表示存储引擎返回的数据在经过过滤后,剩下满足条件的记录数量的比例。
12.Extra
常见的值如下:
1.Using index
表示 SQL 中使用了覆盖索引。
我们在相应的 select 操作中使用了覆盖索引,通俗一点讲就是查询的列被索引覆盖,使用到覆盖索引查询速度会非常快,SQl 优化中理想的状态。
什么又是覆盖索引?
一条 SQL 只需要通过索引就可以返回,我们所需要查询的数据(一个或几个字段),而不必通过二级索引,查到主键之后再通过主键查询整行数据(select * )。
注意:想要使用到覆盖索引,我们在 select 时只取出需要的字段,不可 select *,而且该字段建了索引。
2.Using where
查询时未找到可用的索引,进而通过 where 条件过滤获取所需数据,但要注意的是并不是所有带 where 语句的查询都会显示 Using where。
3.Using temporary
对查询结果排序时,使用了一个临时表,常见于 order by 和 group by。
4.Using filesort
对数据使用了一个外部的索引排序,而不是按照表内的索引进行排序读取。也就是说 MySQL 无法利用索引完成的排序操作成为 “文件排序”。
5.No tables used
我们的查询语句中没有 FROM 子句,或者有 FROM DUAL 子句。
索引
那既然想快速解决这个生产问题,需要针对这张表创建索引,那如何创建呢?
还是先了解一下索引吧。
MySql索引原理
索引的目的就是加快查询速度,可以用字典目录类比,通过目录,可以快速找到字典中的内容。
索引的原理生活中随处可见,吃顿饭总得看个菜单吧,
说白了,就是通过不断的缩小想要获得数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是我们总是通过同一种查找方式来锁定数据。
数据库也是一样,但显然要复杂许多,因为不仅面临着等值查询,还有范围查询 (>、<、between、in)、模糊查询 (like)、并集查询 (or) 等等。数据库应该选择怎么样的方式来应对所有的问题呢?
我们回想字典的例子,能不能把数据分成段,然后分段查询呢?
最简单的如果 1000 条数据,1 到 100 分成第一段,101 到 200 分成第二段,201 到 300 分成第三段…… 这样查第 250 条数据,只要找第三段就可以了,一下子去除了 90% 的无效数据。
所以,索引的本质就是一种排好序的数据结构。
索引的类型
1.HASH
哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似 B + 树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快。
但是,Hash索引并不是最常用的数据库索引类型,尤其是我们常用的Innodb引擎就是不支持hash索引的。
因为存储引擎都会为每一行计算一个hash码,hash码都是比较小的,并且不同键值行的hash码通常是不一样的,hash索引中存储的就是Hash码,hash 码彼此之间是没有规律的,
且 Hash 操作并不能保证顺序性,所以值相近的两个数据,Hash值相差很远,被分到不同的桶中。这就是为什么Hash 索引仅仅能满足 "=",“IN"和”<=>" 查询,不能使用范围查询。
2.B-Tree
三阶B-树
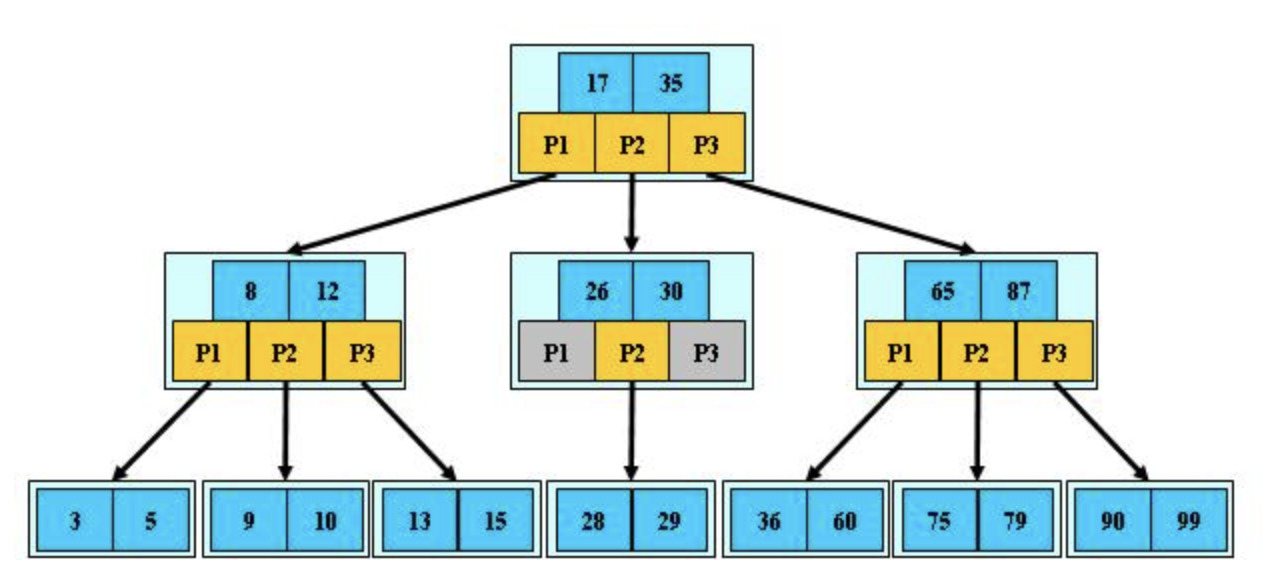
B 树的特征:
关键字集合分布在整颗树中;
任何一个关键字出现且只出现在一个结点中;
搜索有可能在非叶子结点结束;
其搜索性能等价于在关键字全集内做一次二分查找;
自动层次控制;
从B树的结构图中可以看到每个节点中不仅包含数据的 key 值,还有 data 值。
而每页的存储空间是有限的,如果 data 比较大,会导致每个节点的 key 存储的较少,当数据量较大的时候,同样会导致B树很深,从而增加了磁盘 IO 的次数,进而影响查询效率。
3.B+树
三阶B+树
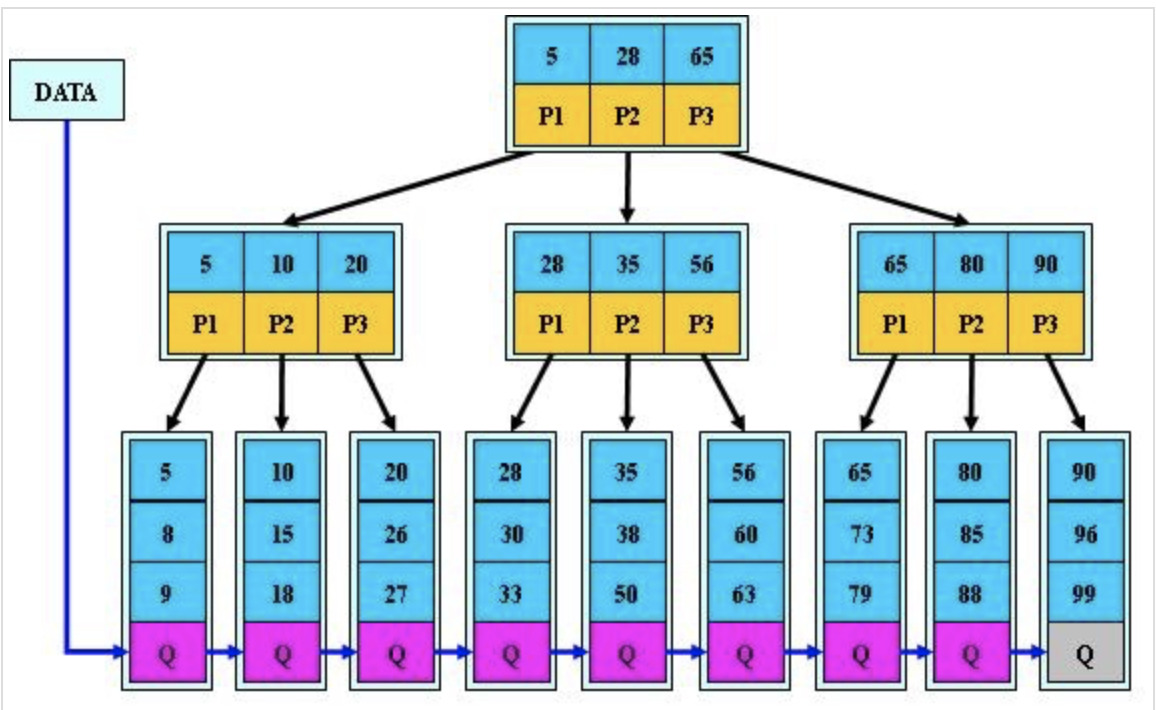
MySQL 中最常用的索引的数据结构是 B+ 树,他有以下特点:
在 B+ 树中,所有数据记录节点都是按照键值的大小存放在同一层的叶子节点上,而非叶子结点只存储key的信息,这样可以大大减少每个节点的存储的key的数量,降低B+ 树的高度
B+ 树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针。
B+ 树的层级更少:相较于 B 树 B+ 每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快
B+ 树查询速度更稳定:B+ 所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定;
B+ 树天然具备排序功能:B+ 树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
B+ 树全节点遍历更快:B+ 树遍历整棵树只需要遍历所有的叶子节点即可,,而不需要像 B 树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
如图所示,如果想要查找数据项38,首先加载第一层的数据至内存,用二分法确定38在28-65之间,由指针p2再次加载下一块数据,再次用二分法判断38在35-56之间,由此数据块的p2指针再次加载下一块数据,二分法最终找到38,得到答案。
总计三次的IO,就找到了数据38。如果数据十分巨大,在如此少的IO情况下快速搜索数据,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次 IO,那么总共需要百万次的 IO,显然成本非常非常高。
通过上面的分析,我们知道 IO 次数取决于 b + 树的高度 h,假设当前数据表的数据为 N,每个磁盘块的数据项的数量是 m,则有 h=㏒(m+1) N,当数据量 N 一定的情况下,m 越大,h 越小;
而 m = 磁盘块的大小 / 数据项的大小,磁盘块的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量越多,树的高度越低。这就是为什么每个数据项,即索引字段要尽量的小,比如 int 占 4 字节,要比 bigint8 字节少一半。
这也是为什么 b + 树要求把真实的数据放到叶子节点而不是内层节点,一旦放到内层节点,磁盘块的数据项会大幅度下降,导致树增高。当数据项等于 1 时将会退化成线性表。
当 b + 树的数据项是复合的数据结构,比如 (name,age,sex) 的时候,b + 数是按照从左到右的顺序来建立搜索树的,比如当 (张三,20,F) 这样的数据来检索的时候,b + 树会优先比较 name 来确定下一步的所搜方向,如果 name 相同再依次比较 age 和 sex,最后得到检索的数据;但当 (20,F) 这样的没有 name 的数据来的时候,b + 树就不知道下一步该查哪个节点,因为建立搜索树的时候 name 就是第一个比较因子,必须要先根据 name 来搜索才能知道下一步去哪里查询。比如当 (张三,F) 这样的数据来检索时,b + 树可以用 name 来指定搜索方向,但下一个字段 age 的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是 F 的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
建索引的几大原则
1. 最左前缀匹配原则,非常重要的原则,mysql 会一直向右匹配直到遇到范围查询 (>、<、between、like) 就停止匹配,比如 a = 1 and b = 2 and c > 3 and d = 4 如果建立 (a,b,c,d) 顺序的索引,d 是用不到索引的,如果建立 (a,b,d,c) 的索引则都可以用到,a,b,d 的顺序可以任意调整。
2.= 和 in 可以乱序,比如 a = 1 and b = 2 and c = 3 建立 (a,b,c) 索引可以任意顺序,mysql 的查询优化器会帮你优化成索引可以识别的形式。
3. 尽量选择区分度高的列作为索引,区分度的公式是 count (distinct col)/count (*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是 1,而一些状态、性别字段可能在大数据面前区分度就是 0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要 join 的字段我们都要求是 0.1 以上,即平均 1 条扫描 10 条记录。
4. 索引列不能参与计算,保持列 “干净”,比如 from_unixtime (create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b + 树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成 create_time = unix_timestamp (’2014-05-29’)。
5. 尽量的扩展索引,不要新建索引。比如表中已经有 a 的索引,现在要加 (a,b) 的索引,那么只需要修改原来的索引即可。
回到开始的慢查询
根据最左匹配原则,最开始的 sql 语句的索引应该是city、province的联合索引;其中字段的顺序可以颠倒,所以我才会说,把这个表的所有相关查询都找到,会综合分析。
那么索引建立成 (city,province) 就是非常正确的,因为可以覆盖到所有情况。这个就是利用了索引的最左匹配的原则。
慢查询优化基本步骤
0. 先运行看看是否真的很慢,注意设置 SQL_NO_CACHE
1.where 条件单表查,锁定最小返回记录表。这句话的意思是把查询语句的 where 都应用到表中返回的记录数最小的表开始查起,单表每个字段分别查询,看哪个字段的区分度最高
2.explain 查看执行计划,是否与 1 预期一致(从锁定记录较少的表开始查询)
3.order by limit 形式的 sql 语句让排序的表优先查
4. 了解业务方使用场景
5. 加索引时参照建索引的几大原则
6. 观察结果,不符合预期继续从 0 分析
Comments | 1 条评论
您好~我是腾讯云开发者社区运营,关注了您分享的技术文章,觉得内容很棒,我们诚挚邀请您加入腾讯云自媒体分享计划。完整福利和申请地址请见:https://cloud.tencent.com/developer/support-plan
作者申请此计划后将作者的文章进行搬迁同步到社区的专栏下,你只需要简单填写一下表单申请即可,我们会给作者提供包括流量、云服务器等,另外还有些周边礼物。[f=wozuimei]